Gtihub 仓库:dataflow-jvm
Abstract
dataflow library provides components and tools to build data processing network, to help programmer build robust, concurrency-enabled applications easily. In other words, users do not need to manually manage task scheduling, even avoid all races under a premise of following certain design specifications and ensure the security of concurrent applications without mutex.
Use case
Unlike traditional imperative programming, programmers who receive data flow ideas write programs by directly describing static data calculation sequences and data transfer relationships. Here is an example:
fun main() = runBlocking {
// initialize
val source = broadcast<Int>()
source - { println(it) }
source - { 2 * it } - { println(it) }
// using
source post 1
// waiting
delay(100)
}
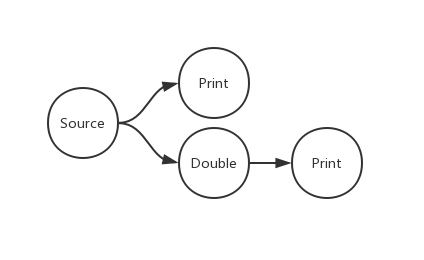
In this example, the initialization code section describes a network with 4 nodes:
- A source node, who transfers number to two child nodes simultaneously
- A action node, print the number
- A transform node, double the number
- Another action node, print the doubled number
In the code that follows, we post a number 1 to the source node. There will be a 1 and a 2 printout on the console. Normally 1 will appear before 2, but not absolute, because the dataflow library has parallelized these two actions.
By parallelization, we can make full use of the CPU’s computing performance, in the low-frequency multi-core architecture of the mobile phone CPU, the benefits brought by parallelization are particularly obvious. Building network construction directly helps programmers better organize logic and avoid the confusion caused by repeated multi-layered function calls and multiple control transferring. The disposable, unsupervised execution style avoids the complexity of process control, and the data flowing between nodes can be considered constant, so that arbitrarily modifying the data at the later stage will not pose a danger to the predecessor.
Terminology
There are some important concepts in the dataflow library:
-
Node
Unlike the parallelized list operation supported by the standard libraries of many languages, dataflow provides coarse-grained parallelism, and nodes are atoms during the parallelization. The node is where the calculation takes place, and the data passing through the node is modified to change their value and type. In addition, unlike the imperative functions which do not manage the returned values at all, nodes also control the way that data is distributed backwards.
According to the behavior of the data entering the node, nodes can be divided into buffed and unbuffered.
According to the operation of data in the node, nodes can be divided into modified and unmodified.
According to the way the data leaves the node, nodes can be divided into cold, normal and broadcast.
-
Link
The links connect nodes and become channels for the data. The data passed through the link can be filtered and counted according to some rules.
-
Post
Data can be passed automatically between nodes in the network, but usually the node will only process the data from other nodes and pass it backwards instead of generating the data itself. The operation to send external data to the network to start processing is called “post”.
Implementation
There are various ways to implement dataflow. The way we selected is to combine the responsive and producer consumer models, that is, the producer informs the consumer when the data is ready, and the consumer requests data from the producer when it is ready to process the data. The producer receives data from outside the network or other nodes, processes it, and then binds an id with the processed data, then informs the consumers it connected to with the id. The consumer immediately saves the id and uses the id to get corresponding data from the producer when it is ready to process it. If the data is still there (not consumed by other consumers and not discarded by the producer), the producer gives the data to the consumer. At which point the consumer becomes a producer, so the above steps will continue.